

Uji 1 sampel kolmogorov-Smirnov digunakan untuk menetahui apakah distribusi nilai-nilai sampel yang teramati sesuai dengan distribusi teoritis tertentu (normal, uniform, poisson, eksponensial). Uji Kolmogorov-Smirnov beranggapan bahwa distribusi variabel yang sedang diuji bersifat kontinu dan pengambilan sampel secara acak sederhana. Dengan demikian uji ini hanya dapat digunakan, bila variabel diukur paling sedikit dalam skala ordinal.
Uji keselarasan Kolmogorov–Smirnov dapat diterapkan pada dua keadaan:
- Menguji apakah suatu sampel mengikuti suatu bentuk distribusi populasi teoritis
- Menguji apakah dua buah sampel berasal dari dua populasi yang identik.
Prinsip dari uji Kolmogorov–Smirnov adalah menghitung selisih absolut antara fungsi distribusi frekuensi kumulatif sampel [S(x)] dan fungsi distribusi frekuensi kumulatif teoritis [Fo(x)] pada masing-masing interval kelas.
Hipotesis yang diuji dinyatakan sebagai berikut (dua sisi):
Ho : F(x) = Fo(x) untuk semua x dari - ~ sampai + ~
Ha : F(x) ≠ Fo(x) untuk paling sedikit sebuah x
Dengan F(x) ialah fungsi distribusi frekuensi kumulatif populasi pengamatan
Statistik uji Kolmogorov-Smirnov merupakan selisih absolut terbesar antara S(x) dan Fo(x), yang disebut deviasi maksimum D.
D = |S(x) – Fo(x)| maks i = 1,2,…,n
Nilai D kemudian dibandingkan dengan nilai kritis pada tabel distribusi pencuplikan (tabel D), pada ukuran sampel n dan a. Ho ditolak bila nilai teramati maksimum D lebih besar atau sama dengan nilai kritis D maksimum. Dengan penolakan Ho berarti distribusi teramati dan distribusi teoritis berbeda secara bermakna. Sebaliknya dengan tidak menolak Ho berarti tidak terdapat perbedaan bermakna antara distribusi teramati dan distribusi teoritis. Perbedaan-perbedaan yang tampek hanya disebabkan variasi pencuplikan (sampling variation).
Langkah-langkah prinsip uji Kolmogorov-Smirnov ialah sebagai berikut:
- Susun frekuensi-frekuensi dari tiap nilai teramati, berurutan dari nilai terkecil sampai nilai terbesar. Kemudian susun frekuensi kumulatif dari nilai-nilai teramati itu.
- Konversikan frekuensi kumulatif itu ke dalam probabilitas, yaitu ke dalam fungsi distribusi frekuensi kumulatif [S(x)]. Sekali lagi ingat bahwa, distribusi frekuensi teramati harus merupakan hasil pengukuran variabel paling sedikit dalam skala ordinal (tidak isa dalam skala nominal).
- Hitung nilai z untuk masing-masing nilai teramati di atas dengan rumus z=(xi–x) /s. dengan mengacu kepada tabel distribusi normal baku (tabel B), carilah probabilitas (luas area) kumulatif untuk setiap nilai teramati. Hasilnya ialah sebagai Fo(xi).
- Susun Fs(x) berdampingan dengan Fo(x). hitung selisih absolut antara S(x) dan Fo(x) pada masing-masing nilai teramati.
- Statistik uji Kolmogorov-Smirnov ialah selisih absolut terbesar Fs(xi) dan Ft(xi) yang juga disebut deviasi maksimum D
- Dengan mengacu pada distribusi pencuplikan kita bisa mengetahui apakah perbedaan sebesar itu (yaitu nilai D maksimum teramati) terjadi hanya karena kebetulan. Dengan mengacu pada tabel D, kita lihat berapa probabilitas (dua sisi) kejadian untuk menemukan nilai-nilai teramati sebesar D, bila Ho benar. Jika probabilitas itu sama atau lebih kecil dari a, maka Ho ditolak
Terdapat beberapa keuntungan dan kerugian relatif uji kesesuaian Kolmogorov-Smirnov dibandingkan dengan uji kesesuaian Kai Kuadrat, yaitu:
- Data dalam Uji Kolmogorov-Smirnov tidak perlu dilakukan kategorisasi. Dengan demikian semua informasi hasil pengamatan terpakai.
- Uji Kolmogorov-Smirnov bisa dipakai untuk semua ukuran sampel, sedang uji Kai Kuadrat membutuhkan ukuran sampel minimum tertentu.
- Uji Kolmogorov-Smirnov tidak bisa dipakai untuk memperkirakan parameter populasi. Sebaliknya uji Kai Kuadrat bisa digunakan untuk memperkirakan parameterpopulasi,dengan cara mengurangi derajat bebas sebanyak parameter yang diperkirakan.
- Uji Kolmogorov-Smirnov memakai asumsi bahwa distribusi populasi teoritis bersifat kontinu.
CONTOH ANALISA SECARA MANUAL:
Berikut ini usia mulai haid pada sejumlah wanita diambil sampel sebanyak 18 orang dengan distribusi sebagaimana tersaji pada tabel berikut :

Ujilah hipotesis nol yang menyatakan bahwa data ini berasal dari suatu populasi berdistribusi normal; diketahui bahwa pada populasi, rata-rata usia mulai haid =12; dengan SD=50.
HIPOTESIS
Hipotesis yang diuji dinyatakan sebagai berikut (dua sisi):
Ho : Kedua sampel berasal dari populasi dengan distribusi yang sama
Ha : kedua sampel bukan berasal dari populasi dengan distribusi yang sama
PERHITUNGAN
Langkah-langkah menghitung nilai-nilai S(xi) dan Fo(xi) :
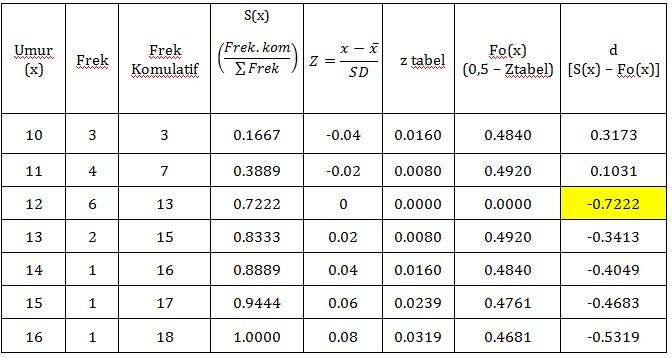
Untuk memeperoleh nilai-nilai Fo(x), pertama-tama yang dilakukan adalah mengkonversikan setiap nilai x teramati menjadi nilai unit variabel normal yang disebut z. Sedang z=(xi–x) /s. dari tabel distribusi kumulatif normal baku (Tabel B), kita temukan luas area dari minus tak terhingga sampai z. luas area tersebut memuat nilai-nilai Fo(x). Selanjutnya kita hitung statistik uji D, dari sekian banyak nilai D ternyata statistik uji D maksimum adalah = 0,7222. Selanjutnya nilai tersebut dibandingkan dengan nilai D tabel (Tabel Kolmogorv-Smirnov).

KEPUTUSAN
Dari tabel D diatas, dengan n=18 dan α (dua sisi) = 0,05 kita dapatkan nilai tabel 0,309. Karena 0,722 > 0,309, maka Ho ditolak, maka kita simpulkan bahwa sampel yang berasal dari populasi tidak dengan distribusi normal.
Blog Biostatistik : http://statistik-kesehatan.blogspot.com/2011/04/uji-kesesuaian-kolmogorov-smirnov.html









